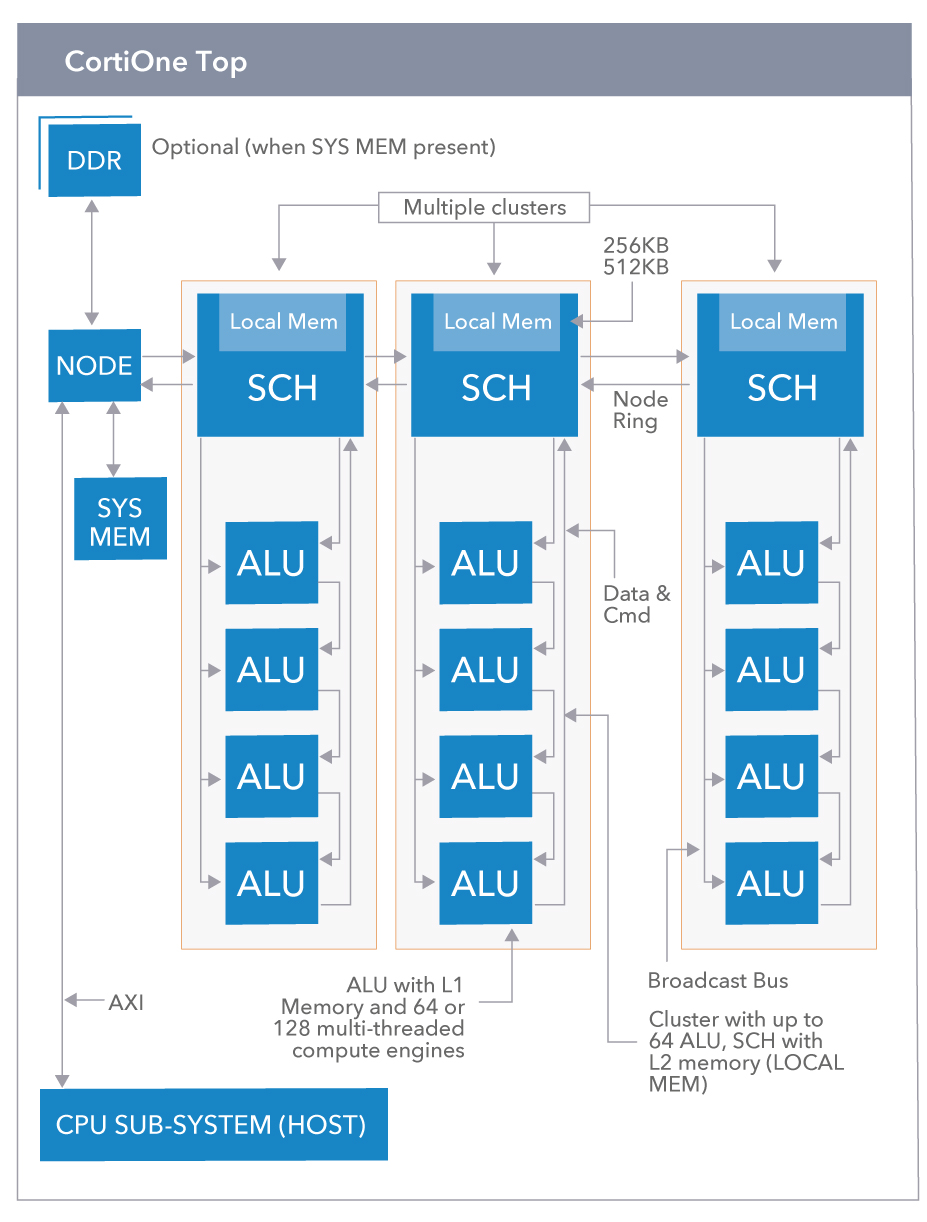
The challenge with AI acceleration is not limited to the hardware, instead we believe software is the biggest challenge. Being able to run any neural network at high utilization (>80%) and low memory usage is the challenge. Feeding the 3-dimensional neural network data using a traditional instruction set makes the compiler intangible in terms of achieving utilization and there by low power and size. CortiCore architecture provides the solution via its unique instruction set that dramatically reduces the compiler complexity. The approach allows us to create a compiler that achieves >80% utilization with 16x reduced memory (compared to currently available solutions) on all neural networks – demonstrated on our FPGA platforms.