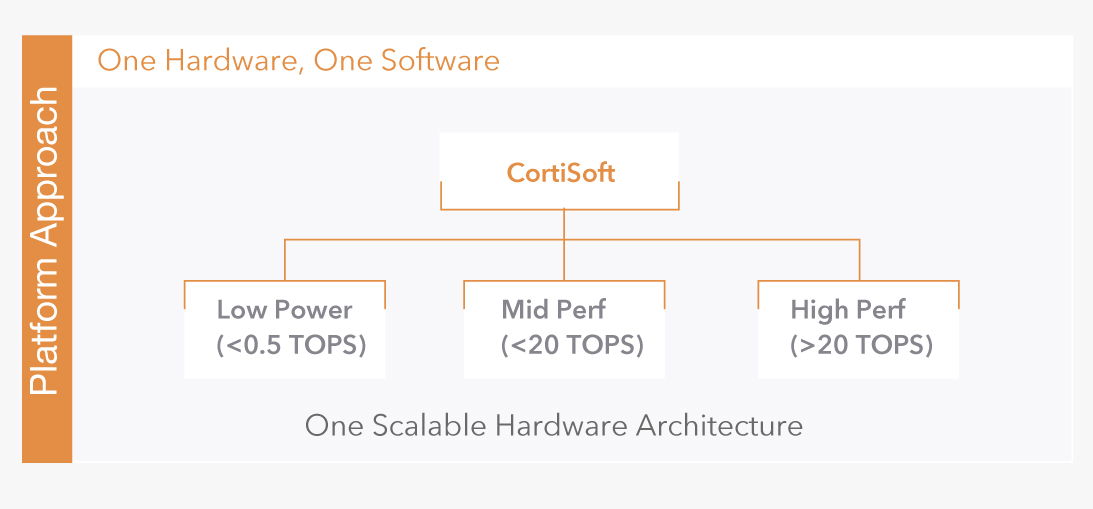
The magic in Roviero’s NPE (Neural Processing Engine) happens in the software
domain by what we call CortiSoft. Our compilers and software tools allow for the porting
of any neural network to run on CortiOne hardware accelerator enabling a highly
efficent compute of large data.